
Mastering the Basics: Understanding Supervised and Unsupervised Learning Algorithms
Supervised learning and unsupervised learning are two main types of machine learning algorithms. While both aim to make sense of data, they go about it in fundamentally different ways. This blog aims to demystify these two types of learning, explore the algorithms that fall under each, and provide practical examples.
Supervised Learning
Supervised learning algorithms are trained on a set of data that has been labeled with the correct output. For example, a supervised learning algorithm could be trained to classify images of cats and dogs. The training data would consist of a set of images, each labeled as either a cat or a dog. The algorithm would learn to identify the features of cats and dogs in the images, and then use those features to classify new images.
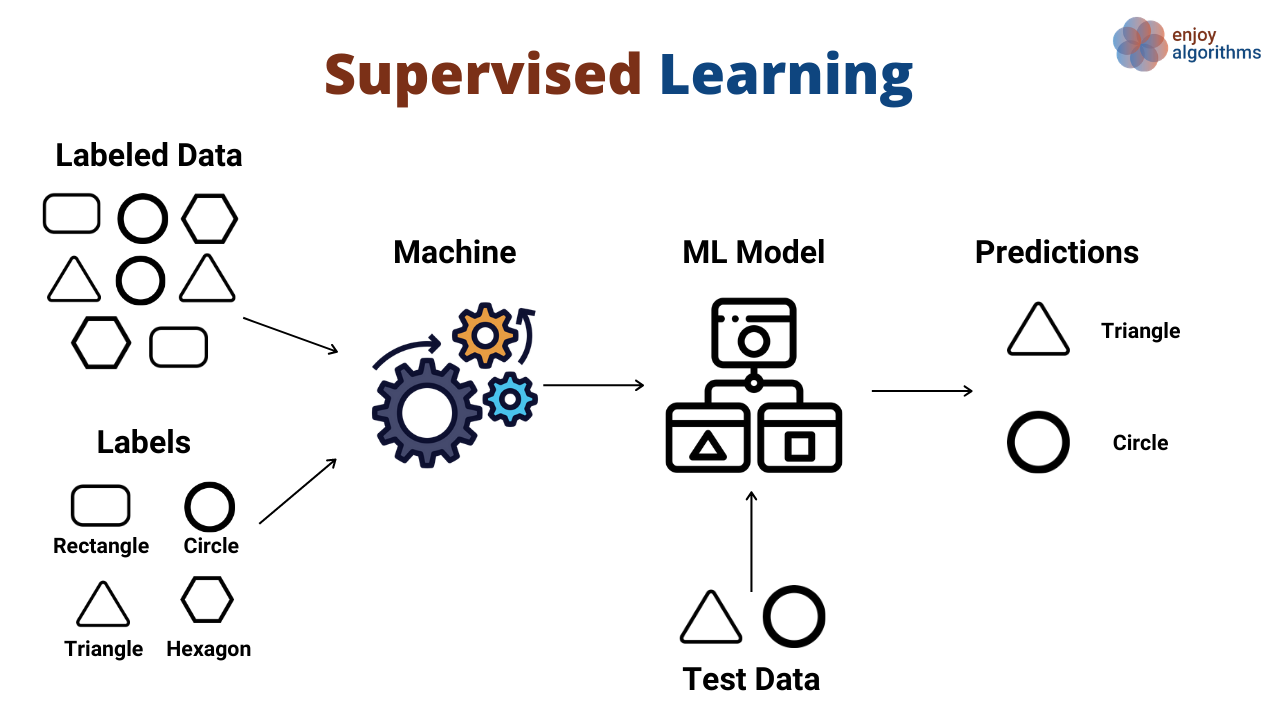
Algorithms
- Linear Regression: Predicts a continuous outcome variable based on one or more predictor variables.
- Decision Trees: Used for both classification and regression tasks.
- Support Vector Machines: Mainly used for classification problems.
- Random Forest: An ensemble of decision trees.
- Neural Networks: Highly flexible algorithms that can learn directly from raw data.
Examples
- Spam Email Filter: Supervised learning algorithms can be used to train spam filters to identify and block spam emails.
- Credit Scoring: Predicting the creditworthiness of a customer.
- Image Recognition: Identifying objects within images.
- Object detection: Identifying and locating objects in images.
- Natural language processing (NLP): Understanding and generating human language.
Pros:
- Easier to understand and interpret.
- High accuracy and reliability when labeled data is abundant.
Cons:
- Requires labeled data, which can be time-consuming and expensive to obtain.
- May not handle unseen data well if not properly generalized.
Unsupervised Learning
Unsupervised learning algorithms are trained on a set of data that has not been labeled. The algorithm must learn to find patterns and relationships in the data without any prior knowledge.
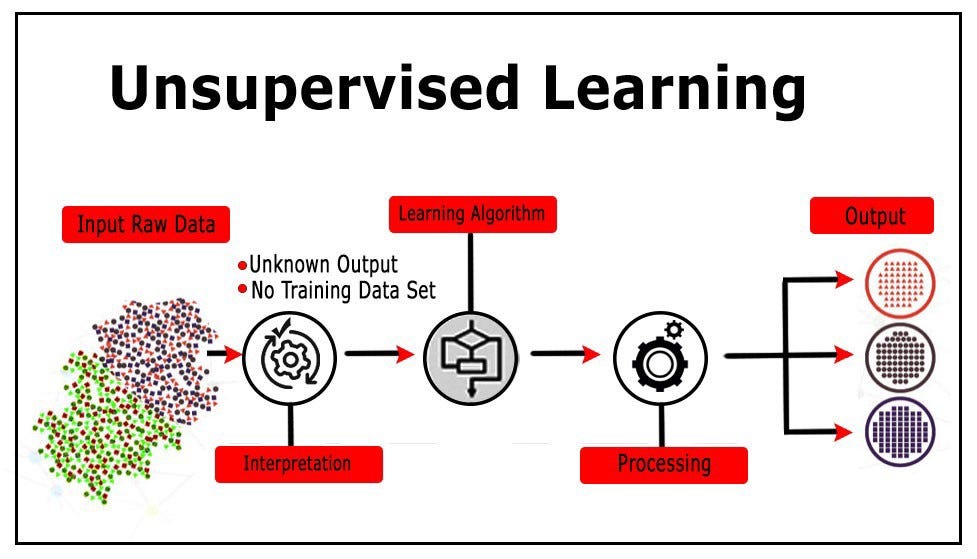
Algorithms
- K-means Clustering: Divides data into non-overlapping subsets.
- Hierarchical Clustering: Builds a tree of clusters.
- Principal Component Analysis (PCA): Reduces the dimensionality of the data.
- Gaussian Mixture Models: Assumes that data is generated from a mixture of several Gaussian distributions.
- t-SNE: Used for dimensionality reduction and visualization.
Examples
- Customer Segmentation: Unsupervised learning algorithms can be used to segment customers into different groups based on their demographics, purchase history, and other factors.
- Anomaly Detection: Unsupervised learning algorithms can be used to detect anomalies in network traffic, such as unusual spikes in traffic or suspicious patterns of activity.
- Market basket analysis: Unsupervised learning algorithms can be used to identify patterns in customer purchase data, such as which products are often purchased together.
- Recommendation systems: Unsupervised learning algorithms can also be used to train recommendation systems. For example, an unsupervised learning algorithm could be used to recommend movies to users based on their ratings of other movies.
Pros:
- Can work with unlabeled data, making it more versatile.
- Good for exploratory analysis to find hidden patterns.
Cons:
- Results can be harder to interpret.
- Less accurate compared to supervised learning for similar tasks.
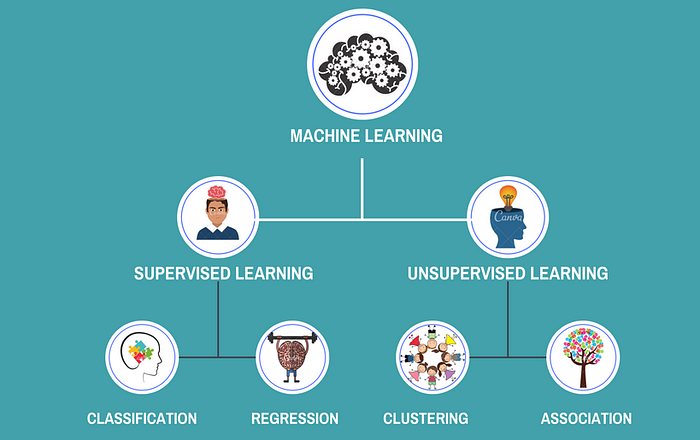

When to Use Which?
- Supervised Learning: When you have a clear goal of predicting a specific outcome and have labeled data to train on.
- Unsupervised Learning: When you’re not sure what you’re looking for and want the algorithm to find natural structures in the data.
Analogies to Understand Better
- Supervised Learning: Think of it like learning to cook with a recipe book. You know what the end dish should look like and have step-by-step instructions (labels) to guide you.
- Unsupervised Learning: Imagine being in a kitchen without a recipe book. You experiment with ingredients and cooking methods to discover new dishes. You don’t know what you’ll end up with, but you learn about the relationships between ingredients.
Conclusion
Both supervised and unsupervised learning have their strengths and weaknesses, and the choice between the two often depends on the specific problem you’re trying to solve. While supervised learning is more straightforward and easier to understand, unsupervised learning offers a way to explore the hidden patterns in data.
